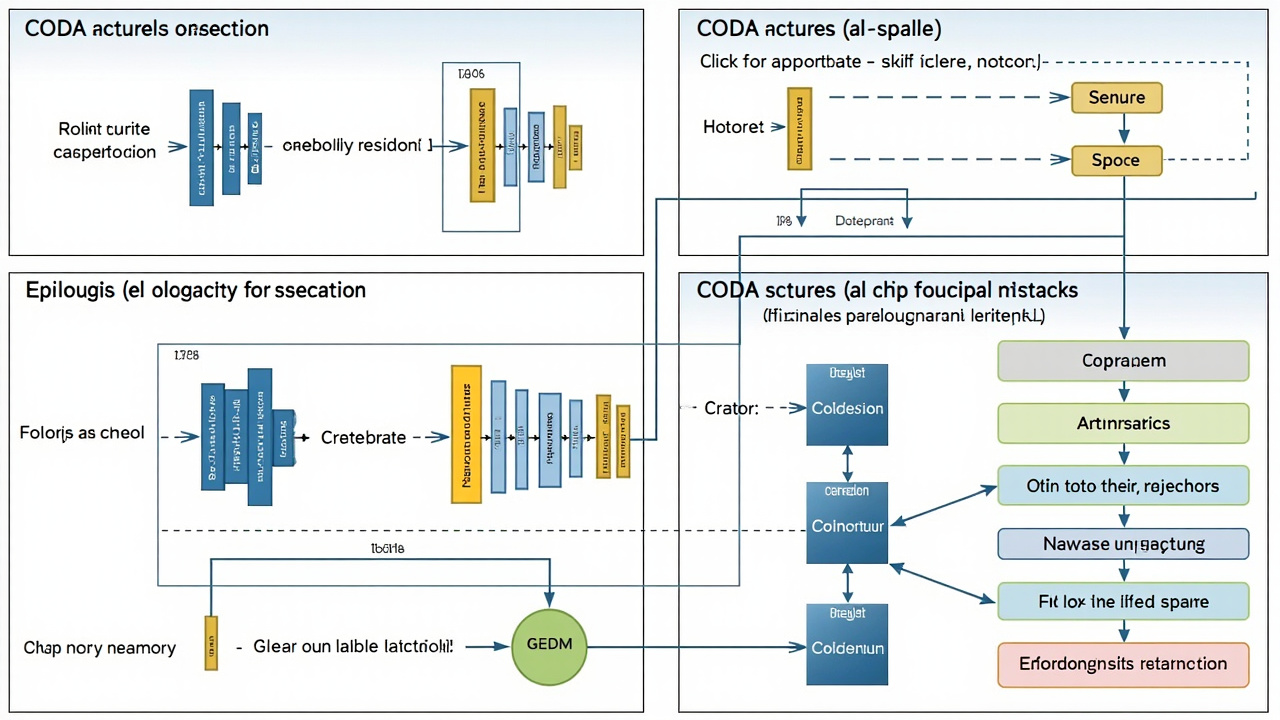
CODA es una nueva abstracción de kernel GPU que revoluciona la forma de ejecutar los componentes no attention de los Transformers. El problema que resuelve es fundamental: mientras que las operaciones de multiplicación de matrices (GEMM) están altamente optimizadas y utilizan eficientemente la memoria del chip, otras operaciones como normalización, activaciones y conexiones residuales requieren mover grandes tensores hacia la memoria global entre cálculos, creando cuellos de botella en el rendimiento. CODA propone una solución elegante: en lugar de ejecutar estas operaciones como kernels separados después de cada GEMM, reparametriza algebraicamente todas estas operaciones para ejecutarse como un 'epílogo' diretamente en el chip, antes de que el resultado del GEMM sea escrito en memoria. Esta abstracción fijael mainloop del GEMM (la parte másheavy computationally) y expone un conjunto pequeño de primitivas de epílogo que permiten escalar, realizar reducciones, transformaciones pairwise y acumulaciones. El resultado es una interfaz constrained que preserva la estructura de rendimiento de GEMMs escritos por expertos pero sigue siendo lo suficientemente expresiva para cubrir prácticamente toda la computación no-attention en los passes forward y backward de un bloque Transformer estándar. Los autores demuestran que kernels CODA, ya sean escritos por humanos o por LLMs, alcanzan alto rendimiento en cargas de trabajo representativas de Transformers, indicando que esta aproximación ofrece un camino práctico para combinar la productividad a nivel de framework con la eficiencia a nivel de hardware.
CODA optimiza Transformers al evitar mover datos a memoria global durante cálculos