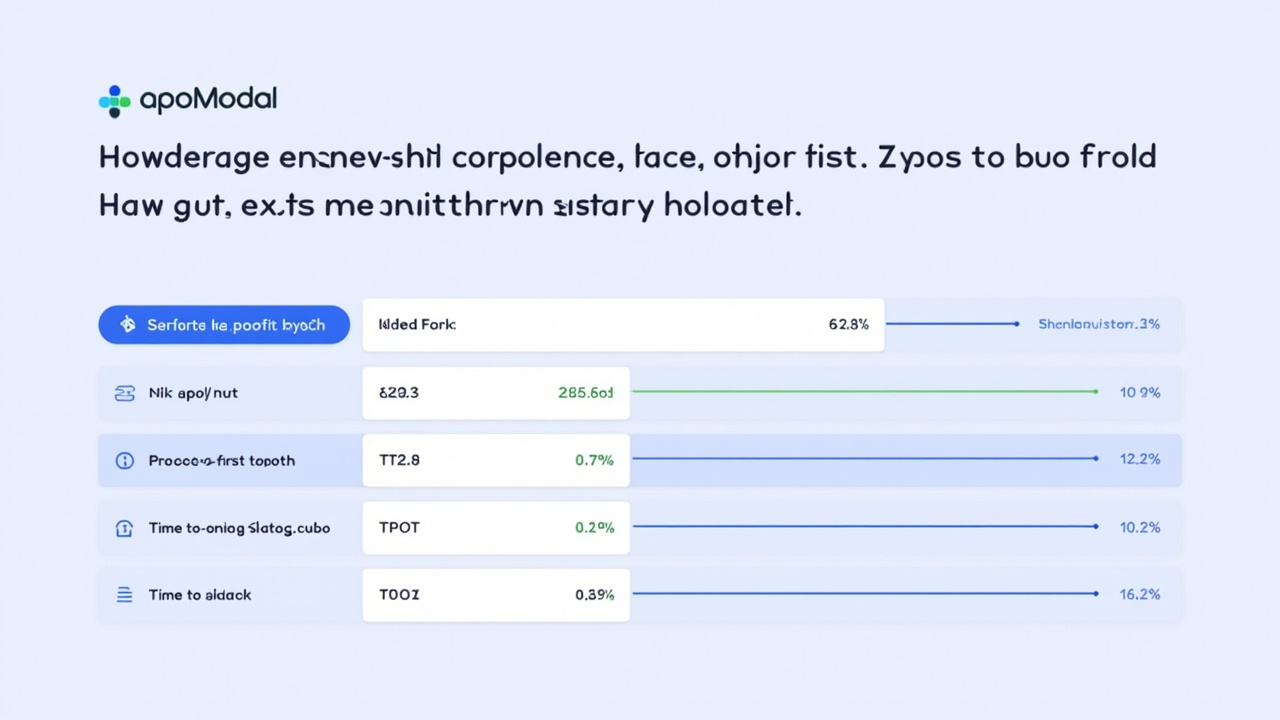
La plataforma Modal ha logrado mejorar el rendimiento de inferencia multimodal en más de un 10% mediante la implementación de un simple diccionario Python en el motor de inferencia SGLang. El cambio, ya integrado en SGLang v0.5.10, aumentó el throughput de solicitudes de 22.2 a 25.7 req/s (un 16.2% más) y redujo la latencia media TTFT de 965ms a 838ms (-13.2%), mientras que el TPOT medio descendió de 72ms a 60ms (-17.2%). El equipo identificó que el cuello de botella residía en la función process_input_requests del scheduler de SGLang, donde se gastaban aproximadamente 3% del tiempo total del scheduler en llamadas repetidas a torch.UntypedStorage._new_shared_cuda para gestionar tensores entre procesos. La solución consistió en implementar una caché simple basada en un diccionario Python para almacenar los handles del pool de memoria GPU, evitando así el trabajo repetitivo de abrir y cerrar los mismos handles en cada iteración. Los modelos vision-language (VLMs) son cada vez más relevantes para aplicaciones como el análisis de documentos no estructurados y agentes de codificación multimodales. Modal subraya que esta optimización demuestra cómo mejoras incrementales y directas pueden generar ganancias significativas en eficiencia de inferencia de IA, siguiendo el principio de 'nunca bloquear la GPU'.
Modal mejora inferencia multimodal más de 10% con un simple diccionario Python