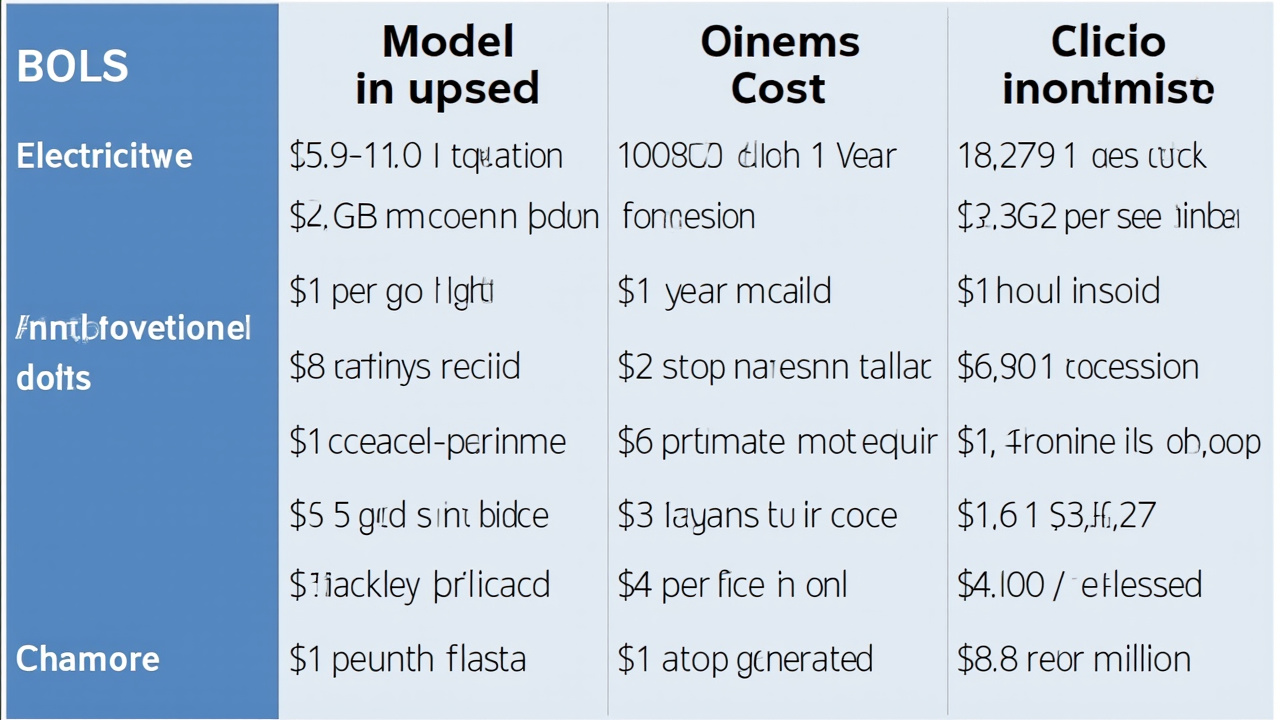
Este artículo analiza la viabilidad económica de ejecutar modelos de lenguaje grandes (LLM) de manera local en un MacBook Pro con chip M5, comparándolo con servicios de inferencia en la nube como OpenRouter. El autor realiza un desglose detallado considerando tres factores principales: electricidad, hardware y rendimiento en tokens por segundo. En cuanto a electricidad, con un consumo de 50-100 watts y un costo de~$0.20 por kilovatio-hora, el gasto energético ronda los $0.02 por hora, lo cual es prácticamente insignificante. El costo del hardware es más significativo: un MacBook Pro M5 Max con 64 GB de RAM cuesta~$4,299. Considerando una vida útil de 5 años, el costo por hora de uso es de~$0.10. En términos de rendimiento, el M5 Max puede procesar entre 10 y 40 tokens por segundo con un modelo como Gemma 4 de 31 mil millones de parámetros, lo que resulta en un costo de $1.61 a $4.79 por millón de tokens generados. OpenRouter, por su parte, ofrece el mismo modelo a~$0.38-$0.50 por millón de tokens y con velocidades 3-7 veces superiores (60-70 tokens/segundo). Esto significa que OpenRouter es aproximadamente un tercio del costo y el doble de rápido. El autor concluye que, aunque localmente es posible ejecutar modelos con rendimiento comparable a Anthropic Sonnet en un dispositivo de consumo, para un empleado típico el costo del tiempo representa 1000 veces más que el costo de los tokens en la nube. Por lo tanto, en contextos profesionales donde el tiempo tiene valor económico significativo, los servicios en la nube resultan más convenientes a pesar de los mayores costos por token.
Ejecutar LLMs en Mac con chip M5 vs OpenRouter: análisis de costos