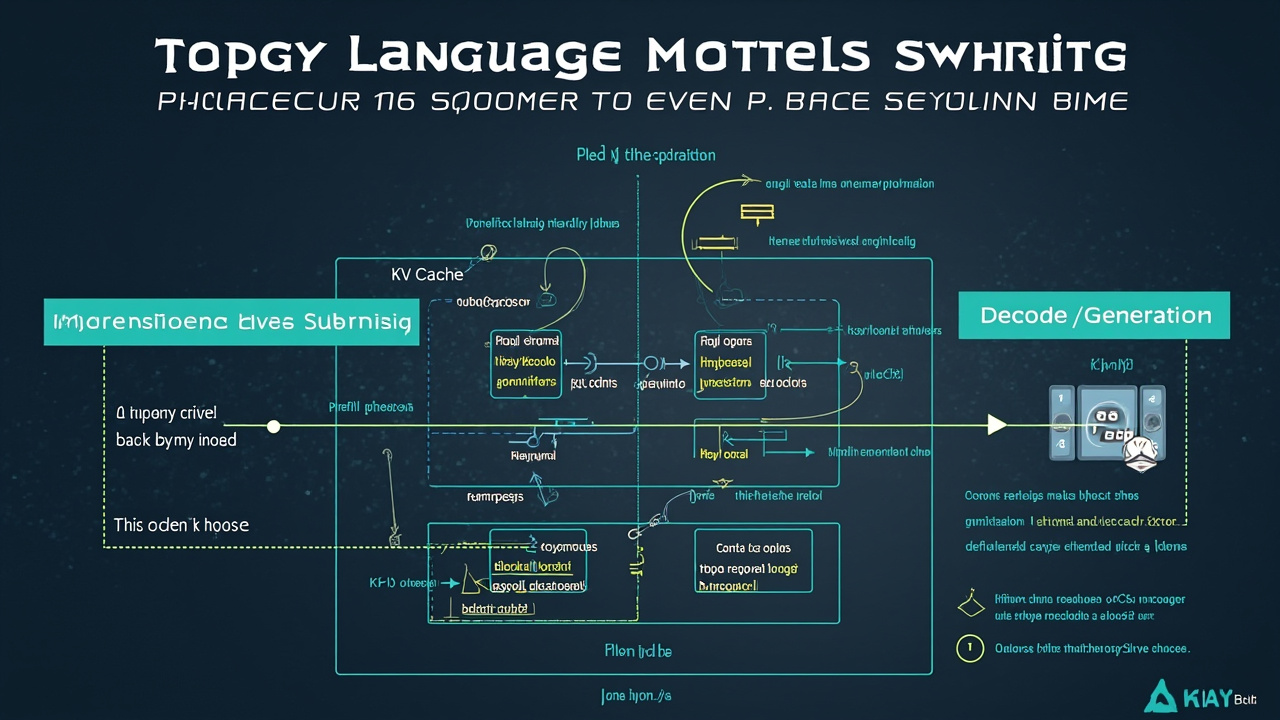
Los transformers autorregresivos son la arquitectura fundamental que permite a los modelos de lenguaje grande (LLMs) generar texto token a token, prediciendo cada siguiente palabra basándose en todo lo previamente generado. Este proceso se divide en dos fases: prefill (preparación) y decode (generación iterativa). Durante el prefill, el modelo procesa todo el prompt de entrada en una única passada paralela, generando los primeros logits para predecir el primer token y, crucialmente, populando el KV Cache con las matrices de clave (K) y valor (V) para cada capa. El KV Cache es la optimización central: almacena los vectores K y V calculados durante el prefill para que las siguientes iteraciones no necesiten recalcular la atención sobre todo el contexto previo. En la fase decode, el modelo procesa un solo token a la vez (de forma secuencial), generando solo su query (Q) mientras lee las matrices K y V almacenadas en caché. Esto reduce drásticamente el costo computacional: donde un forward pass sin caché procesaría N tokens en cada paso, con KV Cache solo procesa 1 token mientras reutiliza el trabajo anterior. El mecanismo de atención funciona proyectando los embeddings mediante matrices aprendidoas (Wq, Wk, Wv), dividiendo en heads paralelas, calculando scores de atención con máscara causal (cada token solo ve los anteriores), aplicando softmax y produciendo representaciones contextuales. Esta técnica es lo que hace viable la generación de secuencias largas en LLMs modernos, reduciendo el tiempo de inferencia de manera significativa y permitiendo aplicaciones prácticas como chatbots y asistentes IA.
Cómo los modelos de lenguaje predicen la siguiente palabra en tiempo real